Mid-Level Visual Priors Improve Generalization and Sample Efficiency for Learning Visuomotor Policies
Abstract
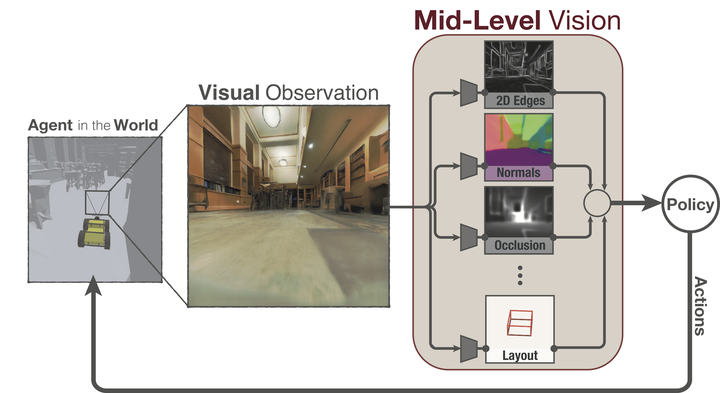
How much does having visual priors about the world (e.g. the fact that the world is 3D) assist in learning to perform downstream motor tasks (e.g. delivering a package)? We study this question by integrating a generic perceptual skill set (e.g. a distance estimator, an edge detector, etc.) within a reinforcement learning framework–see Figure 1. This skill set (hereafter mid-level perception) provides the policy with a more processed state of the world compared to raw images. We find that using a mid-level perception confers significant advantages over training end-to-end from scratch (i.e. not leveraging priors) in navigation-oriented tasks. Agents are able to generalize to situations where the from-scratch approach fails and training becomes significantly more sample efficient. However, we show that realizing these gains requires careful selection of the mid-level perceptual skills. Therefore, we refine our findings into an efficient max-coverage feature set that can be adopted in lieu of raw images. We perform our study in completely separate buildings for training and testing and compare against visually blind baseline policies and state-of-the-art feature learning methods.
Supplementary notes can be added here, including code and math.
Alexander Sax
PhD Student, Computer Science
My research interests include distributed robotics, mobile computing and programmable matter.